
The logistic classifier is similar to equation of the plane.
W is weight vector, X is input vector and y is output vector.
b is bias that to adjust boundary base.
Anyway, this form is context of logistic regression, called logists.
y is result value of vector calculation that is score, that is not probability.
So, to change a probability, use softmax function.

So, we can choose what probability is close to 1.
Softmax example code in python
///scores = [3.0, 1.0, 0.2]
import numpy as np
def softmax(x):
"""Compute softmax values for each sets of scores in x."""
return np.exp(x) / np.sum( np.exp(x), 0 )
print(softmax(scores))
///result is
[ 0.8360188 0.11314284 0.05083836]
Softmax plot example in python
///
# Plot softmax curves import numpy as np import matplotlib.pyplot as plt x = np.arange(-2.0, 6.0, 0.1) scores = np.vstack([x, np.ones_like(x), 0.2 * np.ones_like(x)]) plt.plot(x, scores.T, linewidth=2) plt.show() plt.plot(x, softmax(scores).T, linewidth=2) plt.show()///
first plot is

second plot is
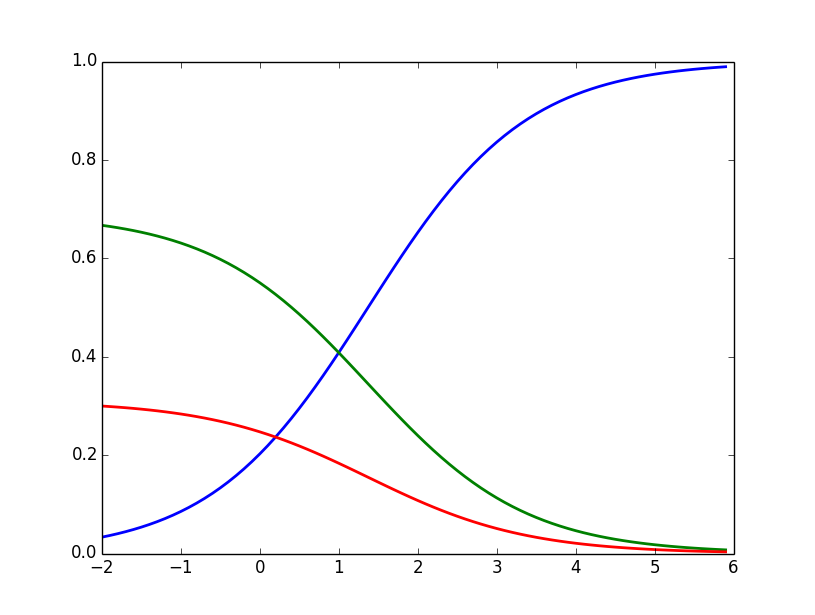
The value of the blue line is grows, lines of green and red is almost close to zero.
one more things,
What happen if scores are multiplied or divided by 10?
///
scores2 = np.array([3.0, 1.0, 0.2]) print( softmax( scores2 * 10)) print( softmax( scores2 / 10))///
[ 9.99999998e-01 2.06115362e-09 6.91440009e-13]
[ 0.38842275 0.31801365 0.2935636 ]
If multiplied by the growing differences
If divided, the smaller the difference.

We can take advantage of these properties.
We'll want our classifier to not be too sure of itself in the beginning. -> divided
And then over time, it will gain confidence as it learns. -> multiply









The information distribution center offloads information from a huge number of sources.data science course in pune
ReplyDeleteSuch a very useful article. Very interesting to read this article. I have learn some new information.thanks for sharing. ExcelR
ReplyDeleteI am impressed by the information that you have on this blog. It shows how well you understand this subject.
ReplyDeletedata analytics courses
Really nice and interesting post. I was looking for this kind of information and enjoyed reading this one. Keep posting. Thanks for sharing.
ReplyDeletebusiness analytics course
data analytics courses
data science interview questions
data science course in mumbai
The information provided on the site is informative. Looking forward more such blogs. Thanks for sharing .
ReplyDeleteArtificial Inteligence course in Mysuru
AI Course in Mysuru
The knowledge of technology you have been sharing thorough this post is very much helpful to develop new idea.
ReplyDeleteData Science Training In Hyderabad
ReplyDeleteNice Blog !good information
data analytics courses
Thank you a lot for providing individuals with a very spectacular possibility to read critical reviews from this site.
ReplyDeletePython Training in Hyderabad
Python Course in Hyderabad
Python Institute in Hyderabad
A debt of gratitude is in order for the data about call communities. It is consistently incredible to find out about this ever-evolving industry.
ReplyDeleteSEO services in kolkata
Best SEO services in kolkata
SEO company in kolkata
Best SEO company in kolkata
Top SEO company in kolkata
Top SEO services in kolkata
SEO services in India
SEO copmany in India
Your article is extremely educational. It's a much needed development from other guessed enlightening substance. Your focuses are novel and unique as I would like to think. I concur with a significant number of your focuses.
ReplyDeleteOnline Teaching Platforms
Online Live Class Platform
Online Classroom Platforms
Online Training Platforms
Online Class Software
Virtual Classroom Software
Online Classroom Software
Learning Management System
Learning Management System for Schools
Learning Management System for Colleges
Learning Management System for Universities
I like viewing web sites which comprehend the price of delivering the excellent useful resource free of charge. I truly adored reading your posting. Thank you! data science training in coimbatore
ReplyDeleteHi, Thanks for giving nice content...
ReplyDeleteData Science Training In Hyderabad
Great post i must say and thanks for the information.
ReplyDeleteData Science Training in Hyderabad
Awesome blog. I enjoyed reading your articles. This is truly a great read for me. I have bookmarked it and I am looking forward to reading new articles. Keep up the good work! cloud computing course in coimbatore
ReplyDeleteGreat blog!!! It is very impressive... thanks for sharing with us...keep posting.
ReplyDeleteBig Data Analytics Training in Hyderabad
Hadoop Training in Hyderabad
I will really appreciate the writer's choice for choosing this excellent article appropriate to my matter.Here is deep description about the article matter which helped me more.
ReplyDeletePMP Certification Pune
I think this is an informative post and it is very useful and knowledgeable. therefore, I would like to thank you for the efforts you have made in writing this article.
Thanks for giving me the time to share such nice information. Thanks for sharing.data science course in Hyderabad
ReplyDeleteAn excellent article, very informative. It is not every day that I have the possibility to see something like this. thanksdata science course in Hyderabad
ReplyDeleteThe content is utmost interesting! I have completely enjoyed reading your points and have come to the conclusion that you are right about many of them. You are great,
ReplyDeleteData Science Training in Hyderabad
I am genuinely thankful to the holder of this web page who has shared this wonderful paragraph at at this place
ReplyDeleteabout us
It’s very informative and you are obviously very knowledgeable in this area. You have opened my eyes to varying views on this topic with interesting and solid content.
ReplyDeletedata science courses
Very nice blogs!!! i have to learning for lot of information for this sites…Sharing for wonderful information.Thanks for sharing this valuable information to our vision. You have posted a trust worthy blog keep sharing, data science courses
ReplyDeleteTruly an amazing site. It helped me a lot to pursue knowledge about data science.Definitely recommending it to my friends. To know more about Online Data Science Course
ReplyDeleteGreat information, I got a lot of new information from this blog.
ReplyDeleteData Science course in Tambaram
Data Science Training in Anna Nagar
Data Science Training in T Nagar
Data Science Training in Porur
Data Science Training in OMR
ReplyDeleteNice article and your explanation way is too good. Thank for that...!
Pega Training in Chennai
Pega Course in Chennai
Excel Training in Chennai
Corporate Training in Chennai
Embedded System Course Chennai
Linux Training in Chennai
Spark Training in Chennai
Tableau Training in Chennai
Oracle Training in Chennai
Oracle DBA Training in Chennai
I was really impressed to see this blog, it was very interesting and it is very useful for all.
ReplyDeletehow to convert list to string in python
data structures using python
polymorphism in oops
numpy in python
python interview questions and answers for testers
convert string to list python
ReplyDeleteI am really happy to say it’s an interesting post to read . I learn new information from your article , you are doing a great job . Keep it up
Data Science Training in Hyderabad
Devops Training in USA
Hadoop Training in Hyderabad
Python Training in Hyderabad
The python programming language is a modern web programming language that was originally conceived and developed by Guido van Rossum in the 1980s. Since that time, Python has evolved into a high-performance programming language that is modular and extensible. data science course in india
ReplyDeleteI’m happy I located this blog! From time to time, students want to cognitive the keys of productive literary essays composing. Your first-class knowledge about this good post can become a proper basis for such people. nice one
ReplyDeletebest online data science courses
New site is solid. A debt of gratitude is in order for the colossal exertion. ExcelR Data Analytics Courses
ReplyDeletehello sir,
ReplyDeletethanks for giving that type of information. I am really happy to visit your blog.Leading Solar company in Andhra Pradesh
ExcelR provides data analytics courses. It is a great platform for those who want to learn and become a data analytics Course. Students are tutored by professionals who have a degree in a particular topic. It is a great opportunity to learn and grow.
ReplyDeletedata analytics courses
data analytics course
Great Post! IT helps me to gain my knowledge. Thanks for Sharing with us .
ReplyDeleteclinical research courses in pune
These courses have been an exceptional learning journey for me. The curriculum's depth, practical exercises, and expert guidance have equipped me with valuable skills in data analysis.
ReplyDeleteData Analytics Courses in Hyderabad
Excellent blog post. Thank you.
ReplyDeleteData Analytics Courses in Hyderabad
It's remarkable to watch how Hadoop's design evolved in reaction to networking technology at the time. I'm looking forward to the next essay on data locality!
ReplyDeleteData Analytics Courses in Delhi
Learned a lot from this post! Logistic classifiers suddenly seem less daunting. Thanks for breaking it down!
ReplyDeleteData Analytics Courses in Nagpur
This blog gave me a clear roadmap to understand logistic classifiers. I used to find them confusing, but now it feels like a piece of cake. Thanks for simplifying deep learning!
ReplyDeleteData Analytics Courses in Nagpur
Thank you for providing a clear and concise explanation of the logistic classifier and its connection to logistic regression. The inclusion of Python code examples and graphical representations enhances understanding. Keep up the good work.
ReplyDeleteIs iim skills fake?
I shall be extremely grateful that the author chose this fantastic post as being pertinent to my issue. The following in-depth explanation of the article's topic was more helpful to me.
ReplyDeleteData Analytics Courses in Agra
This article totally clicked for me! Learning about logistic classifiers made easy here. Can't wait to dive deeper into deep learning now.
ReplyDeleteData Analytics Courses in Varanasi
Deep learning and logistic regression are fascinating topics in the field of machine learning. Your blog post on this subject is likely a valuable resource for those looking to understand how deep learning can be applied to logistic classification problems. Exploring the intricacies of neural networks and their role in logistic regression can provide valuable insights into building more robust predictive models. Keep up the good work in sharing knowledge about this complex but essential area of machine learning!
ReplyDeleteData Analytics Courses in Delhi
The practical approach of these courses, where we worked on real-world projects and hands-on exercises, was a game-changer. It allowed me to gain practical skills and experience that I can directly apply in my career.
ReplyDeleteData Analytics Courses in Trichy
Wow, this article on deep learning and logistic classifiers is absolutely fascinating! The author dives deep into the concepts and provides a comprehensive study log that showcases their journey of understanding this complex topic. If you are interested to know more about Data Analytics Courses In Pune,
ReplyDeleteclick here Data Analytics Courses In Pune
Superb Post! It aids my knowledge acquisition. I appreciate you sharing with us.
ReplyDeleteData Analytics Courses in Agra
Incredible insights! Learning about logistic classifiers in deep learning was like unlocking a secret code to understanding AI. Thanks for breaking it down so simply!
ReplyDeletedata Analytics courses in lisbon
Great blog! Learnt a lot. Thanks!
ReplyDeletedata Analytics courses in lisbon
thanku for sharing this blog. I found this blog very interesting and helpful.
ReplyDeleteData Analytics Courses in Trivandrum
thank you for sharing this blog. I found it very interesting and useful.
ReplyDeleteData Analytics Courses in Trivandrum
Your insights provide valuable guidance to those seeking to leverage this method for predictive modeling.
ReplyDeleteData Analytics Courses In Chennai